Neural Vocoder is All You Need for Speech Super-resolution
in Proceedings of INTERSPEECH 2022, 2022
Author
Haohe Liu, Woosung Choi, Xubo Liu, Qiuqiang Kong, Qiao Tian, DeLiang Wang
Abstract
Speech super-resolution (SR) is a task to increase speech sampling rate by generating high-frequency components. Existing SR methods are trained in constrained experimental settings, such as a fixed upsampling ratio. These strong constraints can lead to poor generalization ability in mismatched real-world cases. In this paper, we propose a neural vocoder based speech super-resolution method (NVSR) that can handle a variety of input resolution and upsampling ratios, and work well on real-world recordings. NVSR consists of a mel-bandwidth extension module, a neural vocoder module, and post-processing. Our proposed system achieves state-of-the-art results in multiple input and target sampling rate settings. On 44.1 kHz target resolution, NVSR outperforms state-of-the-art models WSRGlow and Nu-wave by 8% and 37% respectively on log-spectral-distance and achieves a significantly better perceptual quality. We demonstrate that prior knowledge in the pre-trained vocoder is crucial by performing mel-bandwidth extension with a simple replication-padding method.
[Download the full preprint version]
Evaluation result on VCTK Multi-Speaker testset:
| 44.1 kHz target sampling rate | 16 kHz target sampling rate |
|---|---|
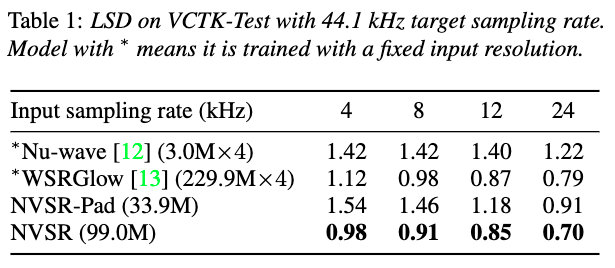 | 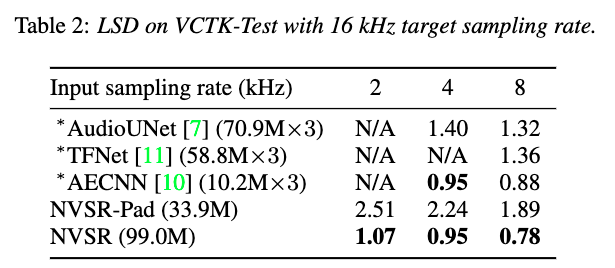 |
Code
Our code is open-sourced at https://github.com/haoheliu/ssr_eval. This repo includes our pre-trained model and a tool for the evaluation of speech super-resolution algorithm.
Quick demo
For more demo, please visit this site
Comparison with SOTA methods on p363_010.wav
| Unprocessed | *Nuwave | *WSRGlow | NVSR (Proposed) | Target | |
| 4kHz | |||||
| Spectrogram |  | 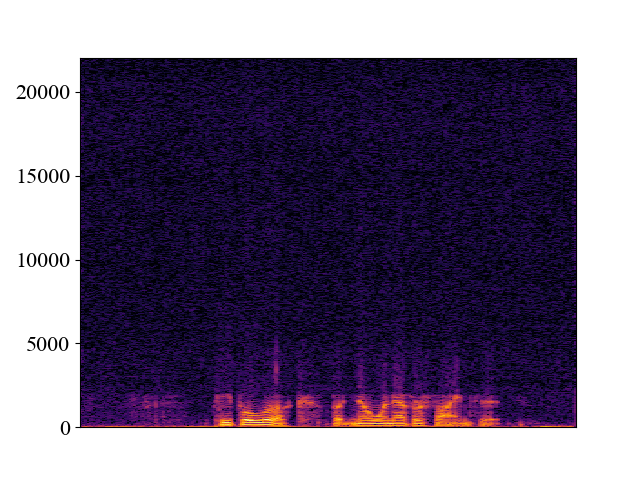 | 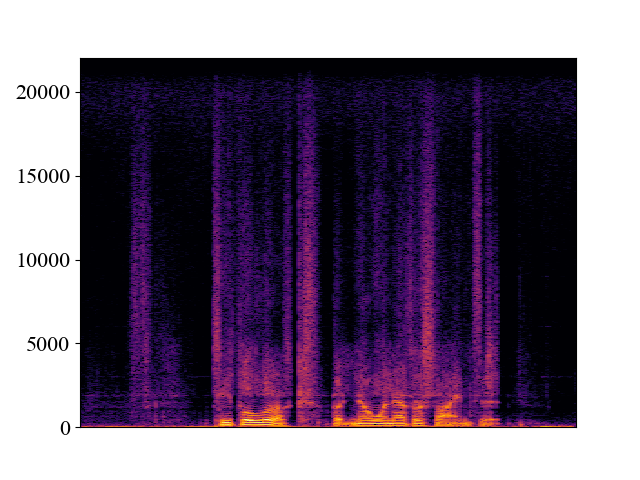 | 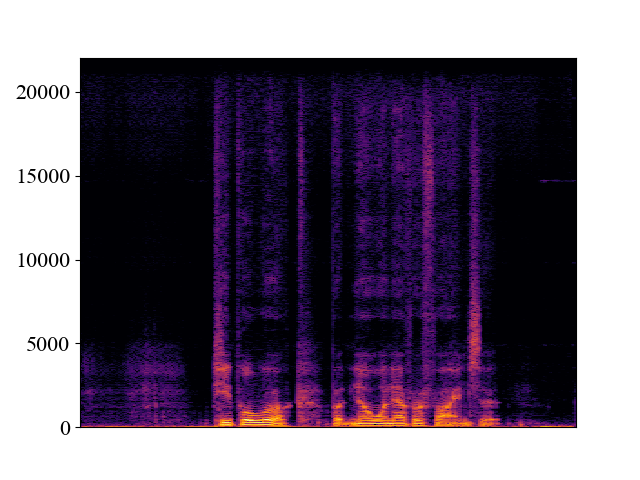 | 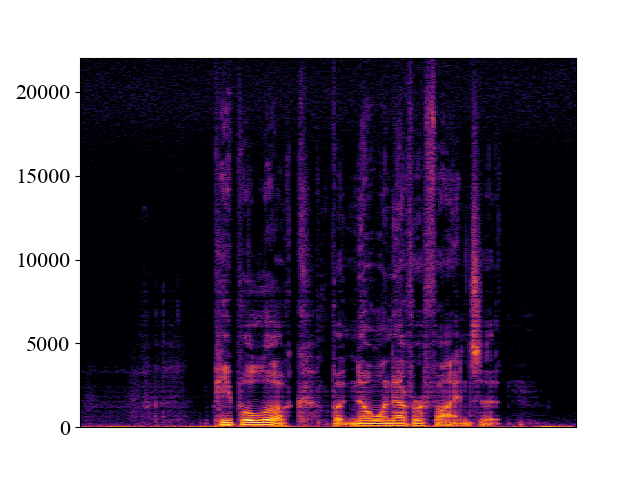 |
| 8kHz | |||||
| Spectrogram | 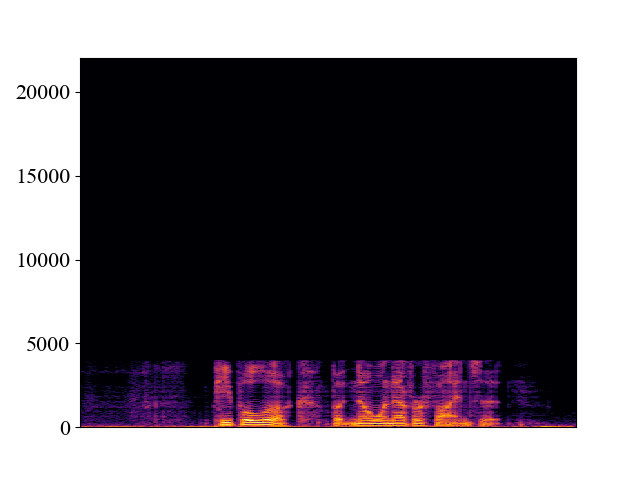 | 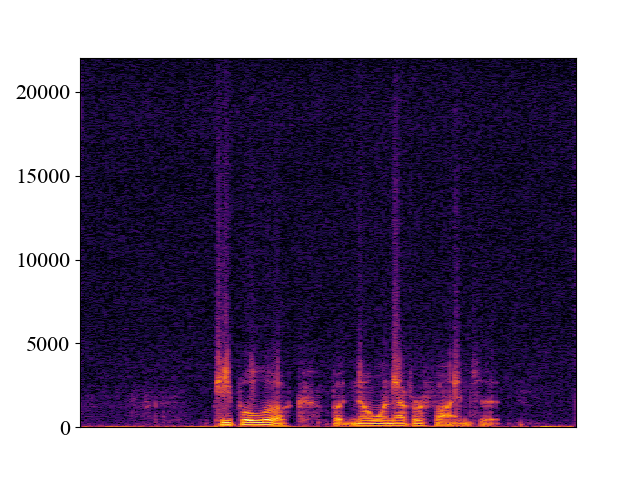 | 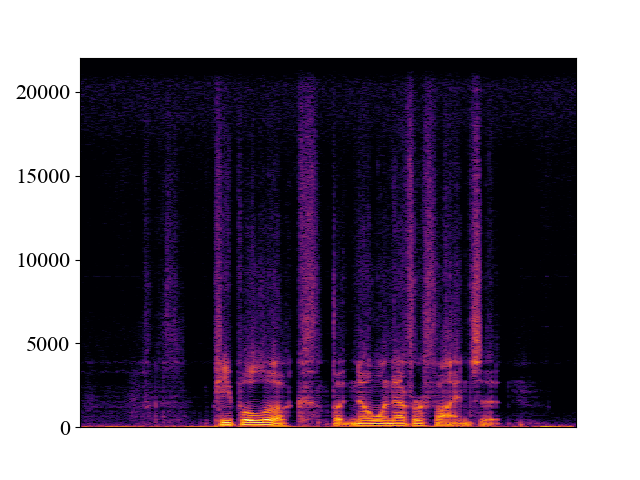 | 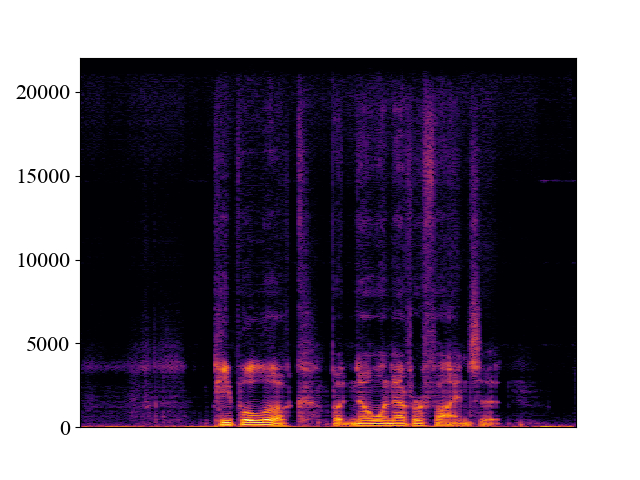 | 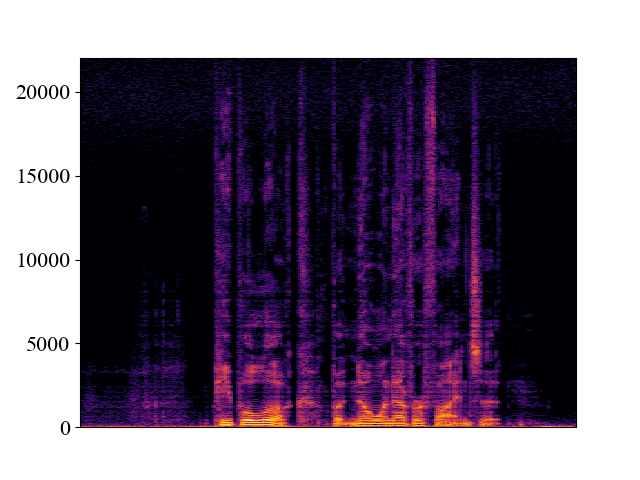 |
| 12kHz | |||||
| Spectrogram | 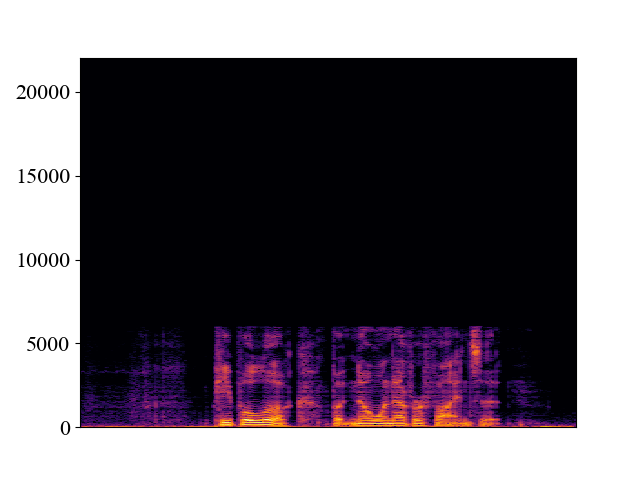 | 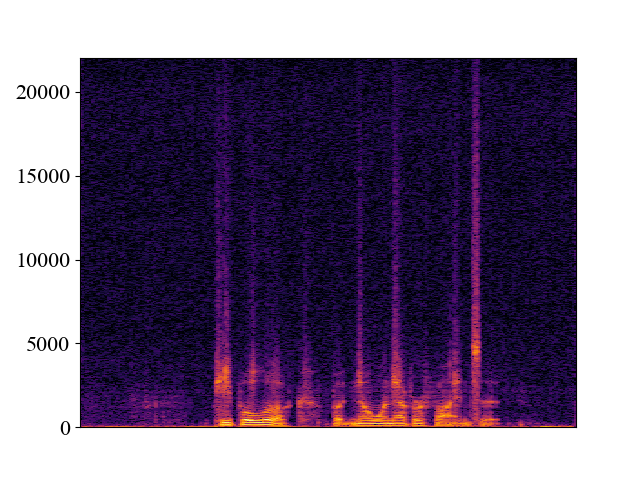 | 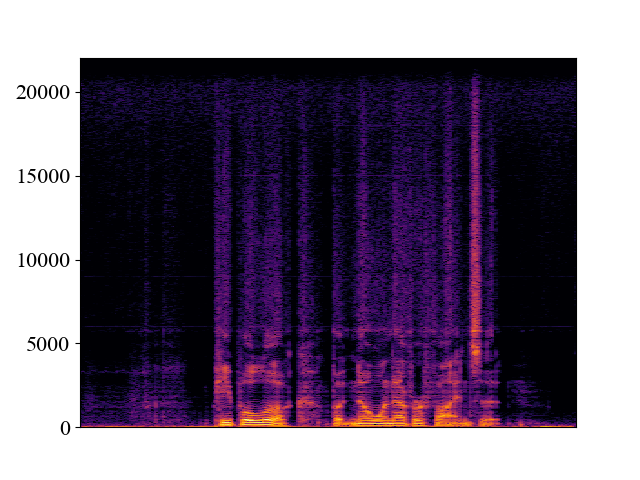 | 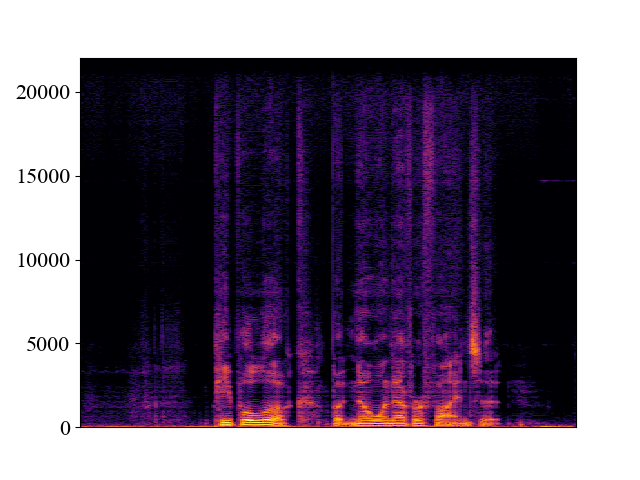 | 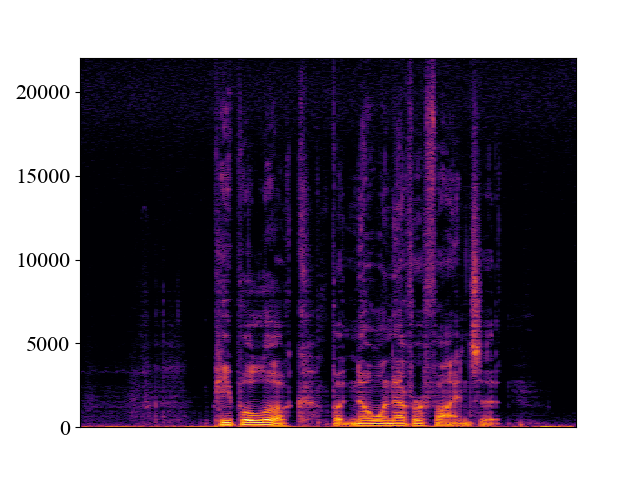 |
The performance of NVSR on different input resolutions on p361_005.wav
| 2kHz | 4kHz | 8kHz | 16kHz | 24kHz | |
| Unprocessed | |||||
| Spectrogram |  |  | 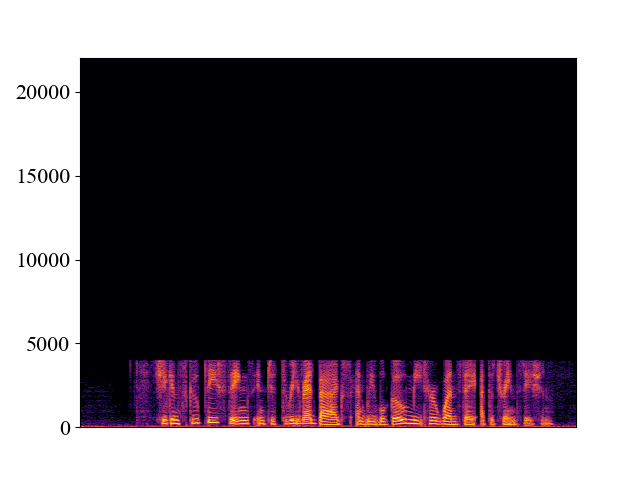 | 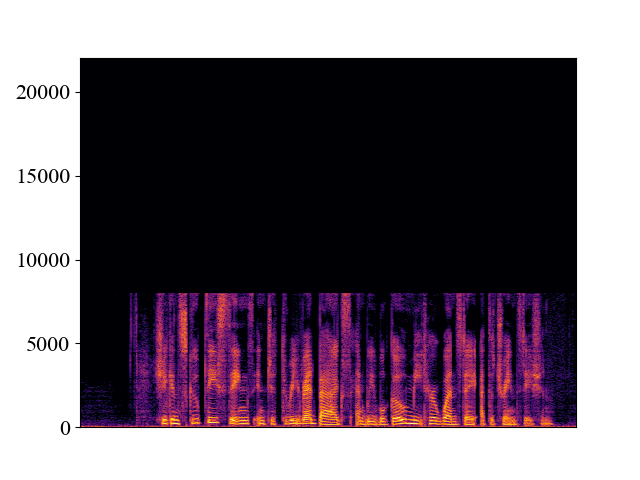 | 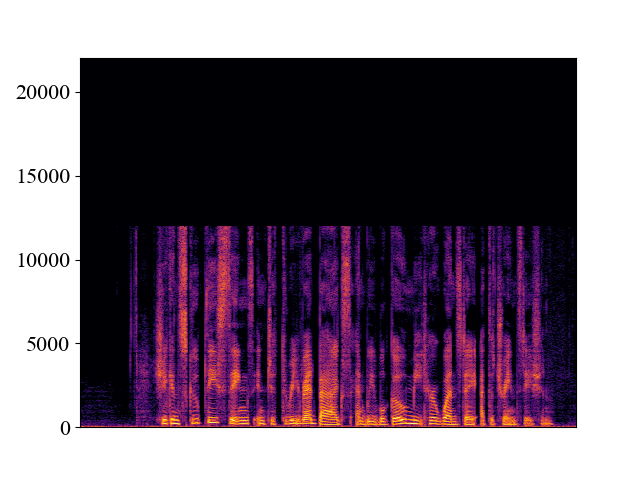 |
| NVSR | |||||
| Spectrogram | 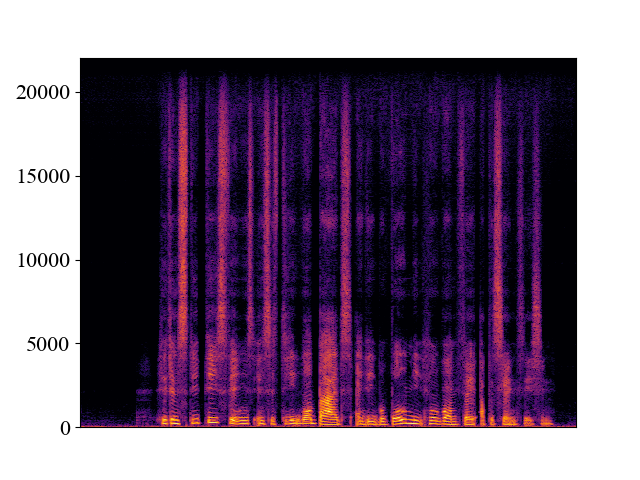 | 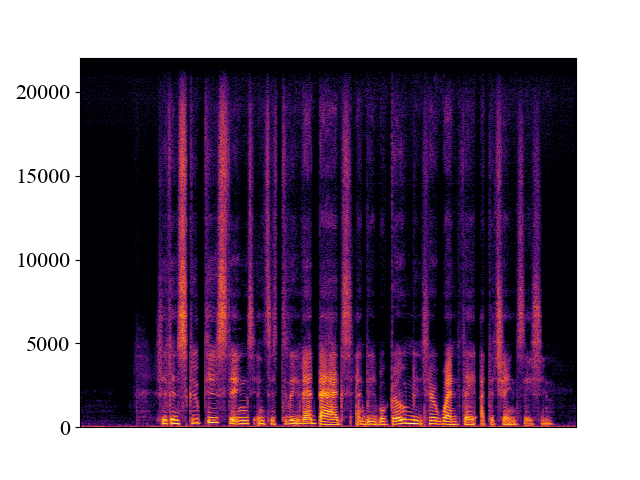 | 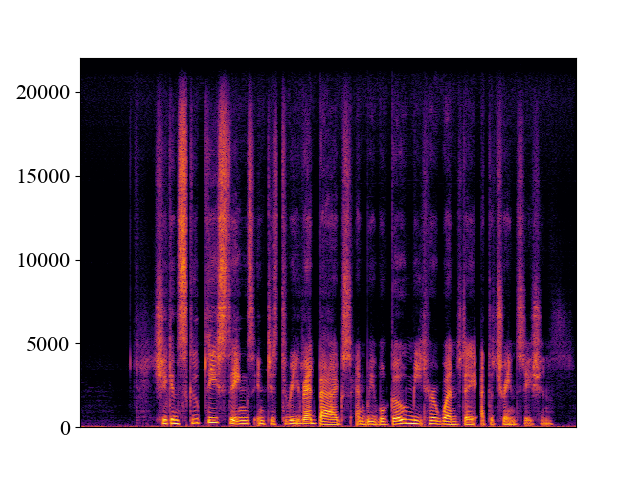 | 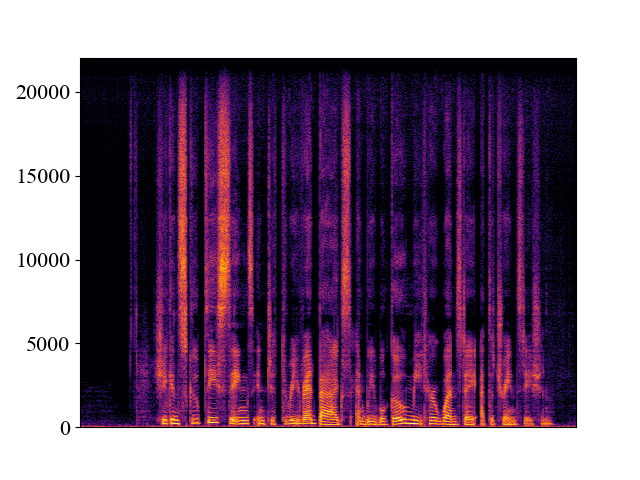 | 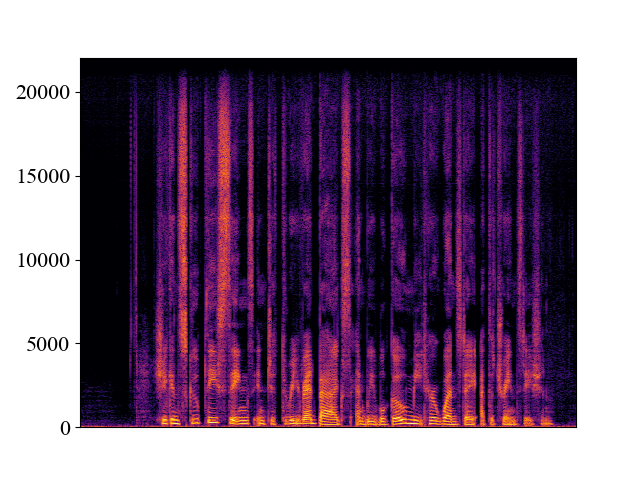 |
| Target | |||||
| Spectrogram | 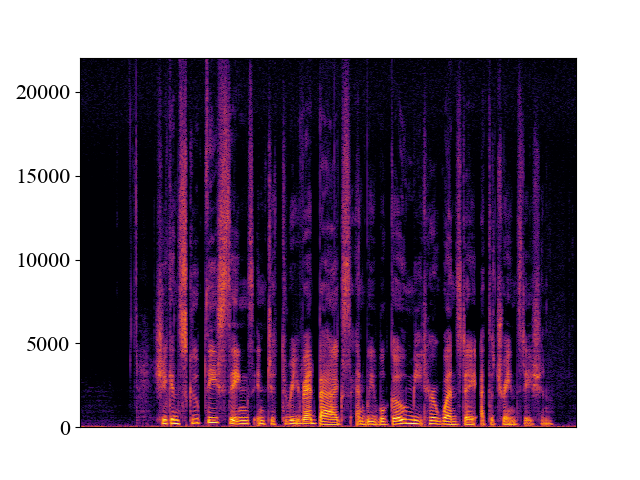 | 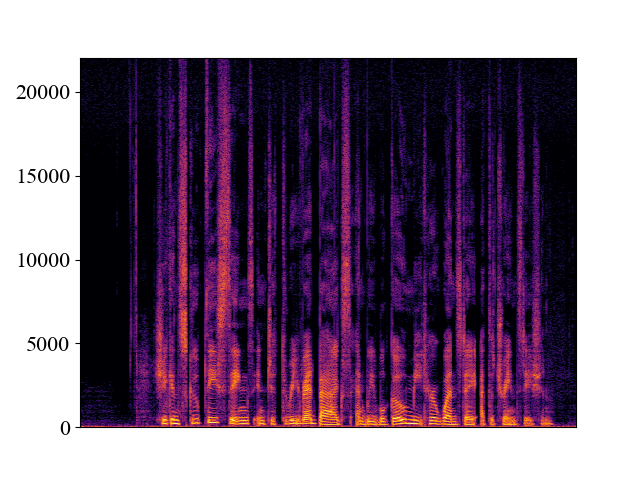 | 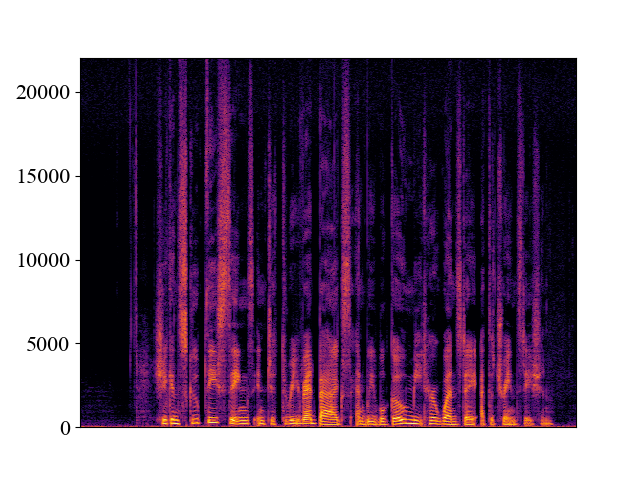 | 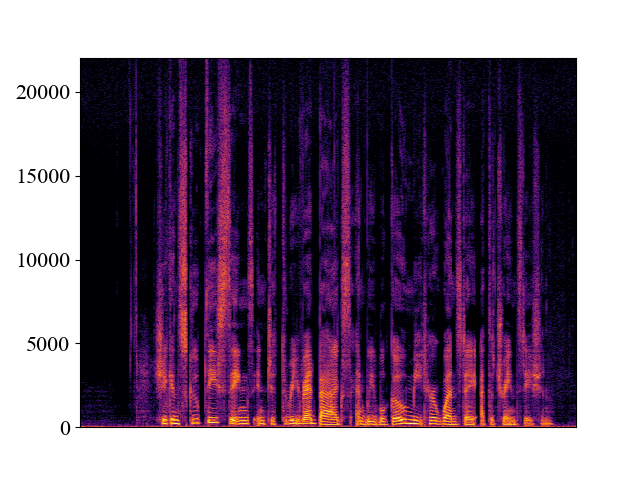 | 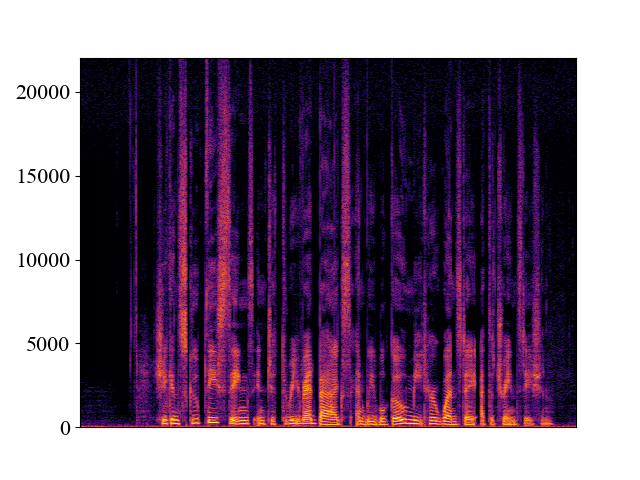 |
Example of bandwidth mismatch cases on p362_016.wav
We can see that if WSRGlow is trained to perform 24kHz -> 48kHz super-resolution. It will fail on the 4kHz and 8kHz mismatch cases.
| Unprocessed | *WSRGlow | Target | |
| Trained_24k_Test_4k | |||
| Spectrogram |  | 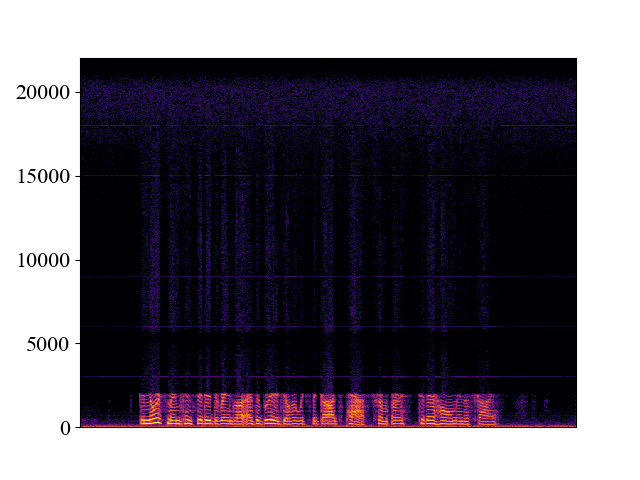 | 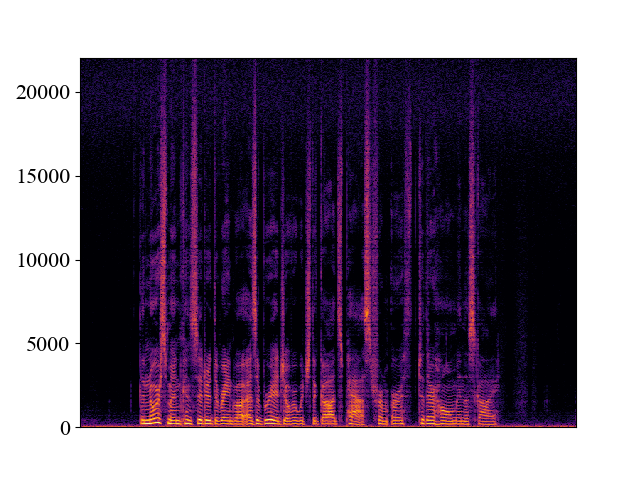 |
| Trained_24k_Test_8K | |||
| Spectrogram |  | 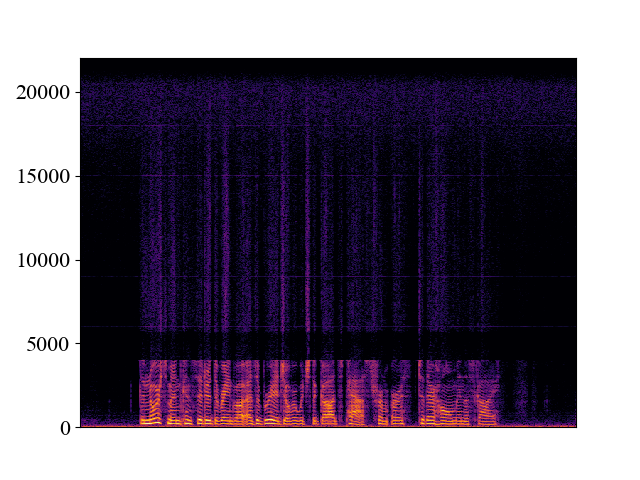 | 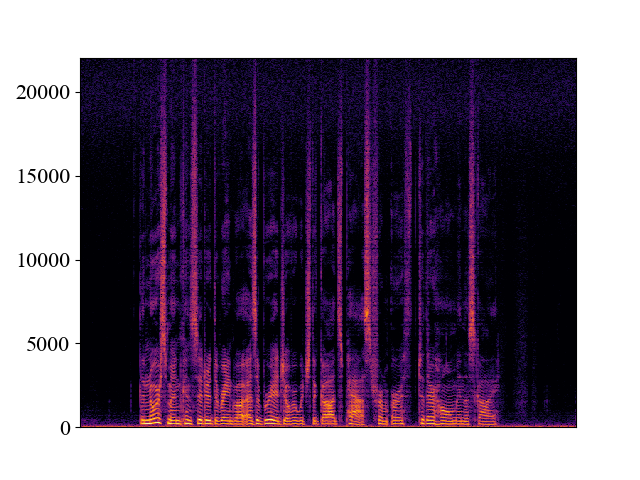 |
Citation
@misc{liu2022neural,
title={Neural Vocoder is All You Need for Speech Super-resolution},
author={Haohe Liu and Woosung Choi and Xubo Liu and Qiuqiang Kong and Qiao Tian and DeLiang Wang},
year={2022},
eprint={2203.14941},
archivePrefix={arXiv},
primaryClass={eess.AS}
}